1. 前言
Java项目中遇到了需要将视频或音频中文字提取的功能,github上已经有了很好的开源模型Faster Whisper实现该功能,可以直接集成到Java项目中使用,这里先做一个简单的使用过程,后续在详细补充。
2. Faster Whisper 模型准备
2.1 安装Faster Whisper
首先确保 Python 环境已经配置好,运行以下命令安装Faster Whisper
pip install faster-whisper2.2 编写Python脚本
from faster_whisper import WhisperModel
import sys
import json
import locale
def transcribe(audio_file_path):
# 加载 Faster Whisper 模型
model = WhisperModel("base", device="cpu") # 可以选择 "cpu" 或 "cuda"
# 转写音频
segments, info = model.transcribe(audio_file_path)
# 提取转写文本并返回
result = []
for segment in segments:
result.append({
'start': segment.start, # 使用属性而不是字典索引
'end': segment.end, # 使用属性而不是字典索引
'text': segment.text # 使用属性而不是字典索引
})
return json.dumps(result, ensure_ascii=False)
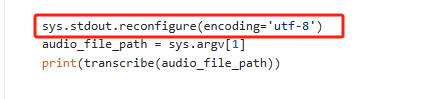
if __name__ == "__main__":
sys.stdout.reconfigure(encoding='utf-8')
audio_file_path = sys.argv[1]
print(transcribe(audio_file_path))
测试是否安装好,运行python代码,python + python脚本路径 + 音频/视频文件
python .\faster_whisper_transcribe.py .\source\aud4.wav如果正常会输出如下格式字符:
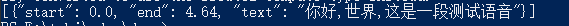
3. Java调用python脚本
可以通过 ProcessBuilder 来调用外部 Python 脚本
package com.tz.test;
import org.junit.jupiter.api.Test;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.nio.charset.StandardCharsets;
public class MyTest {
@Test
public void callPythonScript() throws Exception {
// 构建 Python 脚本的命令
String pythonScriptPath = "E:/tzkj/sdwz/deep/faster_whisper_transcribe.py"; // Python 脚本的路径
ProcessBuilder processBuilder = new ProcessBuilder("python", pythonScriptPath, "E:/tzkj/sdwz/deep/tem/aud1.mp3");
// 启动 Python 进程并获取输出
Process process = processBuilder.start();
StringBuilder output = new StringBuilder();
try (BufferedReader reader = new BufferedReader(new InputStreamReader(process.getInputStream(), StandardCharsets.UTF_8))) {
String line;
while ((line = reader.readLine()) != null) {
output.append(line);
}
}
System.out.println(output);
}
}
4. 注意事项
4.1 编码问题
Python3默认使用的是utf-8编码,如果不是需要在文件头部添加:
# -*- coding: utf-8 -*-转JSON时需要设置使用非ascii编码
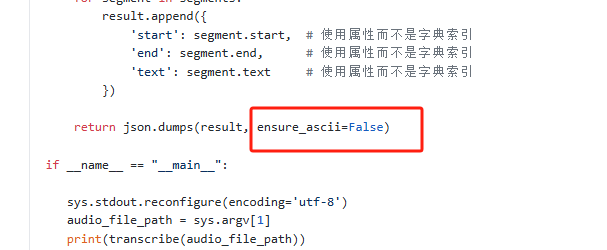
使用读取输出流的方式还要注意python的print使用的是系统默认编码,需要改为utf-8